
谷歌 Gemini 2.5 Pro:重夺 AI 王座的大胆尝试——它能成功吗?
从数据上看,Gemini 2.5 Pro 是谷歌迄今为止最先进的 AI 模型。它拥有强大的推理能力,在数学和科学任务上表现出色,并且可以处理高达一百万个 token 的上下文信息,而且计划翻倍。 谷歌发布 Gemini 2.5 Pro 进行实验,并且现在可以免费使用,这清楚地向 AI 领域表明: 竞争还未结束, 谷歌又回来了。
但是, 产品能达到承诺的水平吗?
随着用户反馈的涌入和各项评测数据的发布,人们的关注点正从最初的发布热潮转向更深入的审视——尤其是那些关注 AI 军备竞赛的商业领袖、开发者和投资者。 以下是对 Gemini 2.5 Pro 值得关注的原因、优势以及需要谨慎之处的详细分析。
1. 内部构造:Gemini 2.5 Pro 的新功能
Gemini 2.5 Pro 不仅仅是版本号的提升, 它是架构上的重大升级,被定位为谷歌 2025 年 AI 战略的支柱。
- 统一的推理能力:Gemini 2.5 Pro 采用增强的推理引擎构建, 使用了改进的强化学习和链式思考方法。 评测数据显示,它在零工具推理任务中处于领先地位。
- 多模态能力:它仍然支持文本、图像、音频和视频输入。 这使 Gemini 在处理需要跨格式综合的复杂数据集方面具有优势。
- 大规模上下文处理:凭借 100 万 token 的上下文窗口(是竞争对手通常提供的两倍),Gemini 针对密集文档、大型代码库和扩展对话进行了优化。 200 万 token 窗口已经在测试中。
- 编码专业知识:该模型在 SWE-bench 验证任务和 Aider Polyglot 等新评测中得分很高。 虽然尚未在自主编码工作流程中占据主导地位,但它正在缩小差距。
- 部署选项:目前可以通过 Google AI Studio 和 Gemini Advanced 免费使用, Vertex AI 集成即将推出。 预计很快将公布完整的商业定价。
2. 评测数据:Gemini 2.5 Pro 的优势
推理和知识
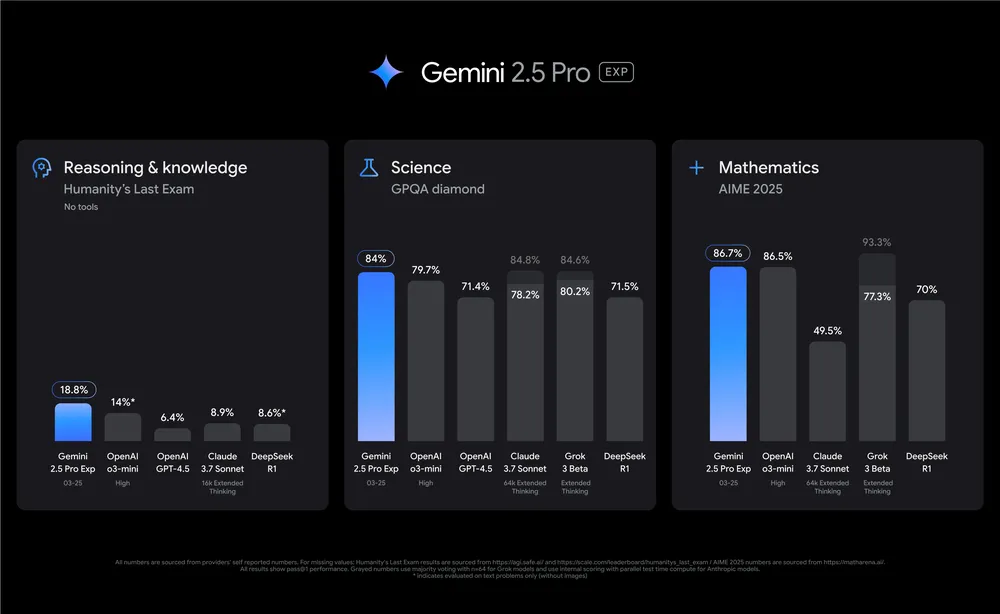
在零样本、无工具的条件下,Gemini 2.5 在复杂推理任务中的得分为 18.8%,是 GPT-4.5 (6.4%) 的三倍, 远超 DeepSeek R1 (8.6%)。 这使其成为企业分析、法律解析和战略建模等领域的强大选择。
数学和科学 (AIME & GPQA)
Gemini 2.5 在 AIME 2024 评测中表现出色, 得分为 92.0%,2025 年为 86.7%。 这远高于 Claude、Grok 甚至 OpenAI 最新的 o3-mini。 对于金融、工程或学术领域的企业来说,这种数学能力可以转化为实际的生产力提升。
多模态理解
视觉推理 (81.7%) 和图像理解 (69.4%) 表明了强大的多模态性能。 值得注意的是,Gemini 2.5 是唯一一个报告了图像理解分数的模型,这使其成为跨格式理解的领导者。
上下文保留
Gemini 在长上下文评测中的得分分别为 91.5% 和 83.1%, 超过了 OpenAI 的 o3-mini(36.3% 和 48.8%)。 这种能力对于法律、技术和研究工作流程至关重要,在这些工作流程中,多文档的一致性至关重要。
多语言能力
Gemini 在 Global MMLU Lite 评测中获得了很高的分数 (89.8%), 这表明它能够处理和推理多种语言,这对于跨国企业和跨国部署来说是一项重要的资产。
3. Gemini 2.5 Pro 仍然不足之处
尽管 Gemini 2.5 Pro 具有优势, 但它并非没有缺陷,尤其是在与利基任务中的竞争对手相比时。
代码生成
虽然它的表现不错(在 LiveCodeBench v5 上为 70.4%), 但它落后于 OpenAI 的 o3-mini(74.1%)。 对于构建自主代码代理或内部工具管道的公司来说,这可能会限制大规模的效率。
自主编码
Gemini 在 SWE-bench 验证评测中获得 63.8% 的分数, 落后于 Claude 的 70.3%。 这一点值得注意,因为企业对“构建 AI 的 AI”的需求持续增长。
事实准确性
在 SimpleQA 上,Gemini 的得分为 52.9%, 低于 GPT-4.5 的 62.5%。 在高信任度应用(金融、医疗保健或客户服务)中,这种准确性差距可能会影响可靠性。
4. 真实世界的反馈:用户和开发者的评价
在 Reddit 和 X(前身为 Twitter)等论坛上, 反应褒贬不一。
- 对力量的赞扬:开发者强调其先进的推理能力和原生多模态, 而其他人则赞扬谷歌 2025 年的知识截止日期——这在市场上尚属首次。
- 对访问和稳定性的批评:用户报告说,各个平台上的可用性不一致, 一些人发现 Gemini 2.5 的性能与 Gemini 2.0 Flash 等早期版本相当。 一个反复出现的评论是:“它感觉更像是一种可靠的改进,而不是一场革命。”
- 开发者担忧:围绕结构化输出(例如 JSON)、部署代理和推出时间表的问题表明, 已宣布的功能与实际效用之间存在不匹配。
5. 竞争格局:行业的一个转折点
AI 领域正朝着专业化而不是规模化方向发展。 Gemini 2.5 Pro 虽然功能强大,但进入的市场是成本效益和垂直优化正在成为真正竞争的领域。
- OpenAI 的 o3 系列继续在自主行为和编码任务方面处于领先地位。
- Claude 3.7 Sonnet 在事实性和自主推理方面仍然很强大。
- DeepSeek R1 正在成为一匹黑马, 以较低的计算成本实现了令人印象深刻的性能, 迫使现有企业重新考虑定价和可访问性。
对于投资者来说,这标志着一个成熟的生态系统。 随着模型在通用评测中接近能力饱和,差异化将来自集成、部署稳定性和每次推理成本的投资回报率。
Gemini 2.5 Pro 是一个明确的信号——但不是最终答案
Gemini 2.5 Pro 是谷歌迄今为止最强大的 AI 模型。 它在推理、长上下文理解和多模态任务方面确立了领先地位。 但它并没有在所有类别中占据主导地位——用户已经在对可用性、完整性和价值提出尖锐的问题。
对于企业来说,Gemini 2.5 Pro 提供了一个引人注目的工具包——尤其是在知识密集型领域。 对于投资者来说,它反映了更广泛的行业转型:从构建 更大 的模型到构建 更好 的模型。
主要要点:
- Gemini 2.5 Pro 是一项技术飞跃,尤其是在推理和上下文丰富的任务中。
- 评测证实了谷歌重新获得的竞争优势——但也强调了事实准确性和自主工作流程中的关键差距。
- 实际应用将取决于交付速度、定价清晰度和与开发者建立信任。